Easier Search Support In Web Apps With The Search Filters DSL (ft. MongoDB)


The @quenk/search-filters module was created to ease the burden of integrating search in Web applications.
Search is a common use case that starts off simple but can quickly get out of hand as an application matures and changes.
Motivation
Let's say we need to build a search front-end for a database. We'll use the National Trust's Asset Register as an example..
A fairly simple design may be to provide a form users fill out where each query parameter sent to the server is either a search term or additional details for executing the search (match any/all etc).
With this approach, a request for search results might look like the following:
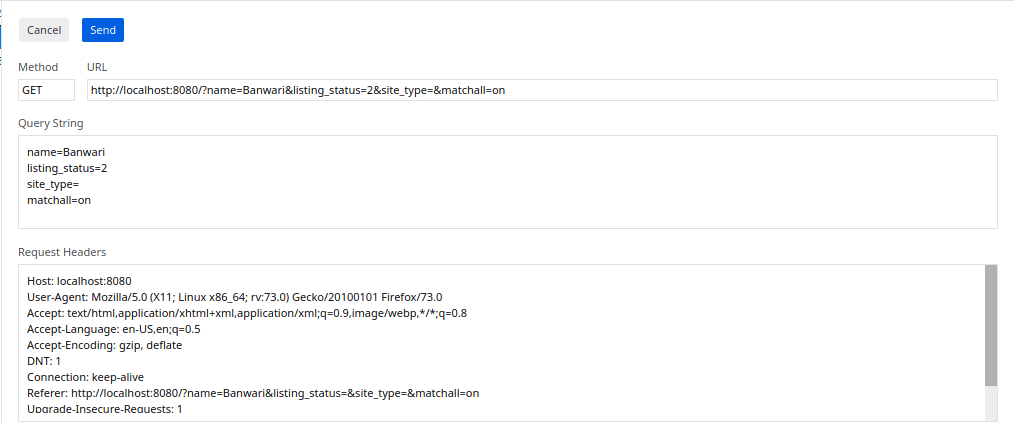
If we are using JSON on the back-end, the query string might be parsed as such:
{
"name": "Banwari",
"listing_status": "2",
"site_type": null,
"matchall": "on"
}
The next step would be to sanitize and validate the query submission to ensure the values provided are safe and the fields specified, correct. After this, we still have to be careful to ensure only the allowed fields are used in our query to prevent any data from being leaked.
As an application grows, all that boilerplate can add to technical debt. Worse when we have to support multiple search endpoints. This type of scenario is what the @quenk/search-filters and related modules were designed to help with.
How It Works
Search Filters works by compiling a small Domain Specific Language (DSL) into valid search terms for the intended target.
The DSL allows us to specify a sequence of "filters" which are composed of field names, operators and the value for the operator. The library is configurable and works on a concept of policies which specify what fields are allowed, their operators and correct value types.
If a user violates any of these, compilation will fail and a search result can be rejected. The DSL also supports the chaining of filters together via a logical "and" or logical "or". This makes the burden of extending the supported fields for search in an application more linear and less tedious.
Until they are compiled, the filters in the DSL are just strings as far as our applications are concerned. This means when submitting our forms, the entire search query can be kept in one flat variable instead of spread across many or nested. This reduces the surface area for error.

The DSL
The Search Filters DSL is documented in the project's README. Here are the major points:
A filter consists of a field name, colon (:), an optional operator and a value:
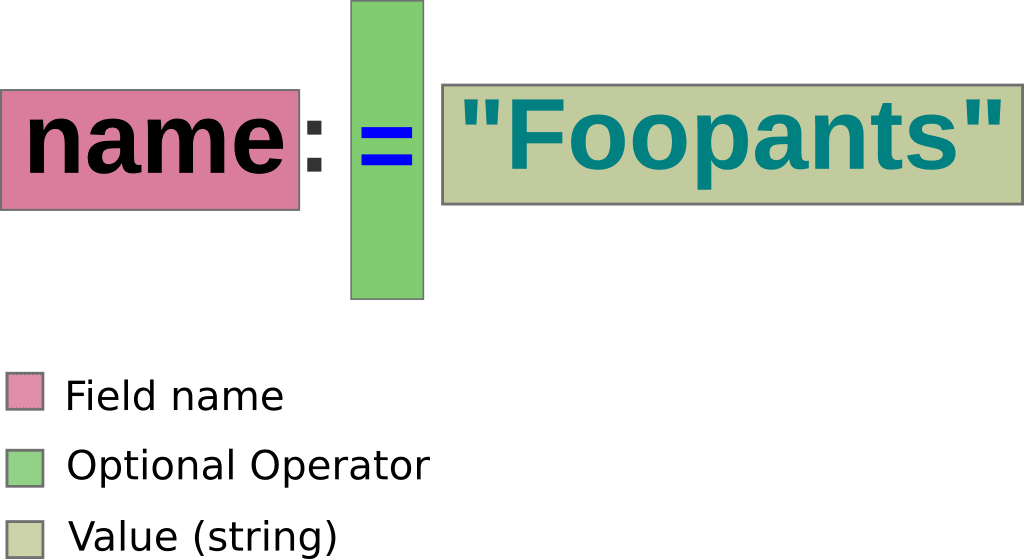
The field name can be a valid ECMAScript identifier or a sequence of identifiers separated by "." (period). The supported operators as of writing are: ">,<,>=,<=,=,!=".
If you don't specify an operator, the default is assumed and is determined by the policies set for the field. Any field encountered that does not have a policy will cause the compilation to fail.
As of writing, the following value types are supported (see the README for specifics): string, number, boolean, date and list.
Filters can be chained together in the DSL using the "and" or "or" keywords or their symbol forms "," and "|" respectively. A search string of more than one filter is essentially a chain of ands or ors.
Putting The DSL To Use
To benefit from the DSL you would need a compiler for your target platform. Implementing a compiler is relatively straightforward and simple however we will leave the details for a future post. Instead we will use the @quenk/search-filters-mongodb module that implements a compiler for the mongodb driver.
Continuing with our National Trust Asset Register example, let's assume we have the following schema for simplicity sake:
interface HeritageAsset {
name: string,
listing_status: number,
site_type: string
}Before we write anymore code we need come up with our search policy.
In establishing our policy, we may decide that users can only search by "name" and "listing_status", nothing else. The way policies are applied during compilation, it is an error to supply any field that does not have a matching policy. That means that if we omit "site_type" from our policy, any user search that includes it will be rejected.
The "name" property is of type string. People are unlikely to enter the exact name we have stored in our database so we want to provide some level of flexibility. To do this, we will then convert searches on the "name" property to a $regex query so we can present results that appear to be close.
Our policies so far looks like this:
import {Value} from '@quenk/noni/lib/data/jsonx';
const policiesEnabled = {
name: {
type: 'string',
operators: ['='],
term: (field:string, op:string, value: Value) =>
new SomeFilterTermInstance(field,op,value);
}
}This will restrict the name value type to string and only allow the = operator which becomes the default operator by virtue of being the first operator in the list. The SomeFilterTermInstance will need to be a class that implements the Term interface from the @quenk/search-filters module. This class will be responsible for sanitizing and constructing our regular expression.
The example above is the direct form of declaring a policy for "name". The compiler supports another way to reduce boilerplate however. Policies can be specified as strings, if they are, they are treated as pointers to policies defined elsewhere and are resolved during compilation.
The @quenk/search-filters-mongodb module ships with some predefined policies that we can use right away. The match policy is similar to what we have defined for "name" so we can replace its definition with the string "match". We can also use the number policy for the "listing_status" field:
const policiesEnabled = {
name: 'match',
listing_status: 'number'
}Now that we have our policies, we can start compiling queries. First we will create a new instance of the exported MongoDBFilterCompiler:
import {MongoDBFilterCompiler} from '@quenk/search-filters-mongodb';
const mfc = new MongoDBFilterCompiler();The MongoDBFilterCompiler constructor accepts three different values, each with defaults. The first is a partial Options instance which can be used to set configuration options for the compiler.
The second is a table of AvailablePolicies. These are what the compiler will use to turn our match and number into actual policy definitions. Specifying policies here allows us to add our own AvailablePolicies to the one provided by the module. The final argument is a TermFactory instance which is used by the underlying compiler to generate the logical operations when needed. This is usually overridden.
With this MongoDBFilterCompiler instance and our policiesEnabled configuration, we are now ready to compile queries. Let's look at what that may look like in a simple express app:
const policiesEnabled = {
name: 'match',
listing_status: 'number'
}
const mfc = new MongoDBFilterCompiler();
app.get('/api/v1/assets', (req: Request, res:Response) => {
if(typeof req.query.q !== 'string') return res.sendStatus(400);
let eResult = mfc.compile(policiesEnabled, req.query.q);
if(eResult.isLeft()) {
console.error(eResult.takeLeft().message);
return req.sendStatus(400);
} else {
getCollection()
.find(eResult.takeRight())
.toArray()
.then(data => req.status(200).json({data}));
}
});Note: Some parts omitted for brevity, also note that if we wanted to add support for "site_type" or any other field, we only need to update our policies. Not logic.
A GET request to our endpoint with query string parameter q containing name:"Bunsee",listing_status:>1 will pass the following query to mongodb:
{
"$and":[
{"name":{"$regex":"Bunsee"}},
{"listing_status":{"$gt":1}}
]
}We then send whatever results we receive to the user.
That's it! That concludes or tutorial on using the @quenk/search-filters DSL. Stay tuned for a follow up post on creating a compiler!